In our first AI Notes piece, we wrote about how the popular rise of ChatGPT and the subsequent opening up of OpenAI’s API led to the proliferation of GPT apps, not all of which have proven to be quite accurate or secure, especially the consumer facing ones that are not used for specific contexts.
At the same time, many businesses have been able to leverage GPT (be it with their own models or OpenAI’s) in a more specific and secure manner, developing internal tools and customer service features primarily to deliver curated/personalized outputs faster, whether that’s on market information (BloombergGPT), designs and formatting (Notion, Canva), or omnichannel customer engagement campaigns (WIZ.AI’s TalkGPT).
We also dipped our hands into this and made our own GPT-powered website chatbot with the primary goal of being able to talk about Insignia Ventures (i.e., primarily information from our website as context) and share some insights to founders (i.e., primarily views on financial management from Insignia Business Review, as we launched the chatbot in our last Insignia Founders Club event on the topic).
And so for this week’s AI notes, we list down five key learnings from the experience, both from the perspective of developing the chatbot and linking specific context to OpenAI’s language model to developing the context itself in such a way that would make it more cost-efficient and still effective for the overall user experience.
Before going any further, if you haven’t tried out the bot, you can chat with it on https://insignia.vc.
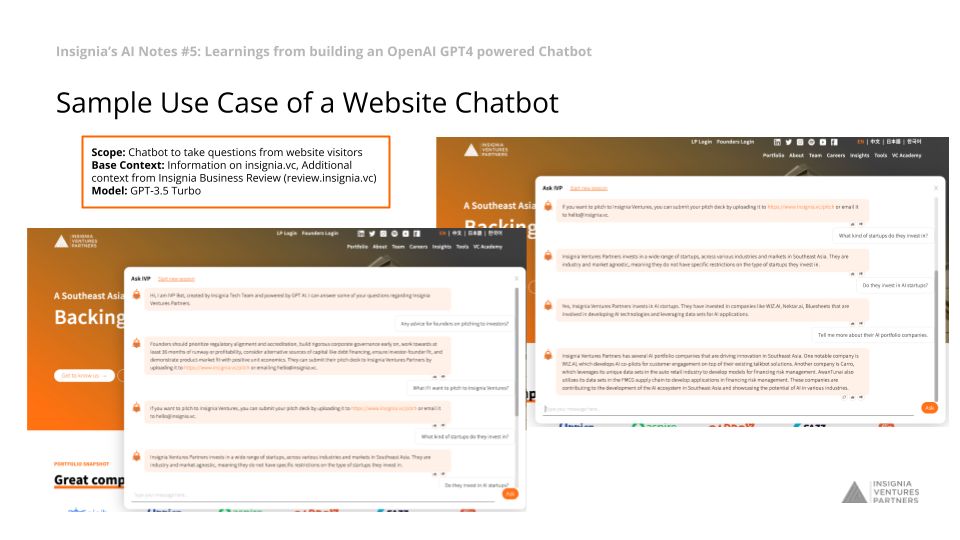
Sample Use Case of a Website Chatbot
Scope: Chatbot to take questions from website visitors
Base Context: Information on insignia.vc, Additional context from Insignia Business Review (review.insignia.vc)
Model: GPT-3.5 Turbo
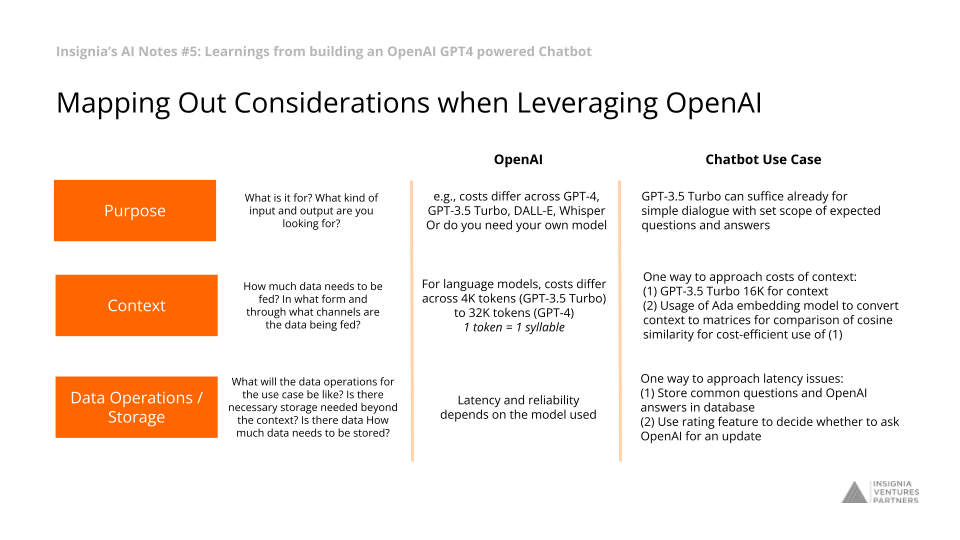
Mapping Out Considerations when Leveraging OpenAI
(1) Purpose: What is it for? What kind of input and output are you looking for?
OpenAI: e.g., costs differ across GPT-4, GPT-3.5 Turbo, DALL-E, Whisper…or do you need your own model
Website Chatbot Use Case: GPT-3.5 Turbo can suffice already for simple dialogue with set scope of expected questions and answers
(2) Context: How much data needs to be fed? In what form and through what channels are the data being fed?
OpenAI: For language models, costs differ across 4K tokens (GPT-3.5 Turbo) to 32K tokens (GPT-4), 1 token = 1 syllable
Website Chatbot Use Case:
One way to approach costs of context:
(1) GPT-3.5 Turbo 16K for context
(2) Usage of Ada embedding model (also by OpenAI) to convert question and context (per paragraph) to matrices for comparison of cosine similarity. This way GPT is only called upon to factor in the context to which the question is most similar, hence making the use of GPT more cost-efficient. To make comparison even more efficient, one can use categorization or adding weights to specific types of contexts.
*Cosine similarity in layman’s terms: often used way to measure how similar or different two text phrases are
(3) Data Operations / Storage: What will the data operations for the use case be like? Is there necessary storage needed beyond the context? Is there data How much data needs to be stored?
OpenAI: Latency and reliability depends on the model used
Website Chatbot Use Case:
One way to approach latency issues:
(1) Store common questions and OpenAI answers in database
(2) Use rating feature to decide whether to ask OpenAI for an update
5 Learnings: Sky’s Not the Limit (Consider Budgets, Model, and Use Case)
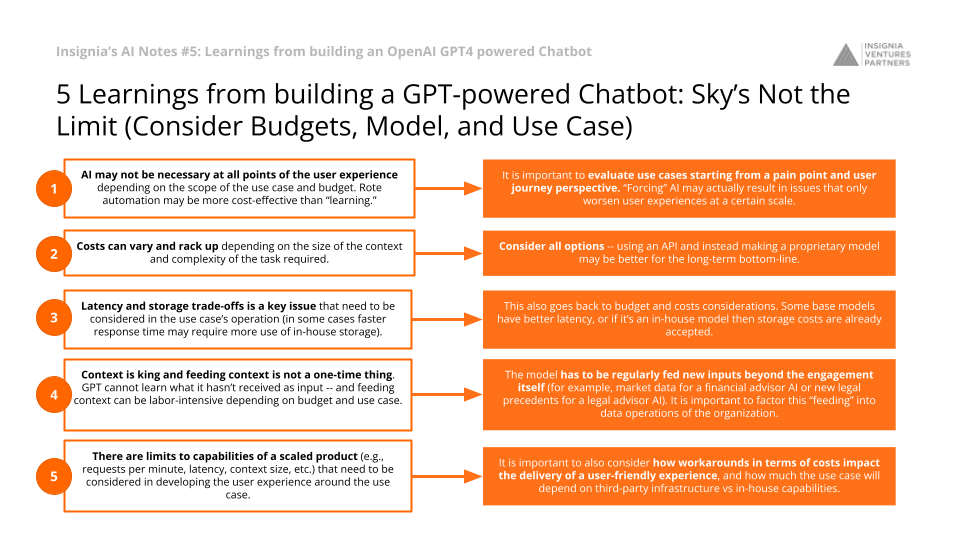
(1) AI may not be necessary at all points of the user experience depending on the scope of the use case and budget. Rote automation may be more cost-effective than “learning.” It is important to evaluate use cases starting from a pain point and user journey perspective. “Forcing” AI may actually result in issues that only worsen user experiences at a certain scale.
(2) Costs can vary and rack up depending on the size of the context and complexity of the task required. Consider all options — using an API and instead making a proprietary model may be better for the long-term bottom-line.
(3) Latency and storage trade-offs is a key issue that need to be considered in the use case’s operation (in some cases faster response time may require more use of in-house storage). This also goes back to budget and cost considerations. Some base models have better latency, or if it’s an in-house model then storage costs are already accepted.
(4) Context is king and feeding context is not a one-time thing. GPT cannot learn what it hasn’t received as input — and feeding context can be labor-intensive depending on budget and use case. The model has to be regularly fed new inputs beyond the engagement itself (for example, market data for a financial advisor AI or new legal precedents for a legal advisor AI). It is important to factor this “feeding” into data operations of the organization.
(5) There are limits to capabilities of a scaled product (e.g., requests per minute, latency, context size, etc.) that need to be considered in developing the user experience around the use case. It is important to also consider how workarounds in terms of costs impact the delivery of a user-friendly experience, and how much the use case will depend on third-party infrastructure vs in-house capabilities.
Follow our LinkedIn page for the latest updates on our weekly AI insights and other insights in Southeast Asia’s innovation landscape.
Paulo Joquiño is a writer and content producer for tech companies, and co-author of the book Navigating ASEANnovation. He is currently Editor of Insignia Business Review, the official publication of Insignia Ventures Partners, and senior content strategist for the venture capital firm, where he started right after graduation. As a university student, he took up multiple work opportunities in content and marketing for startups in Asia. These included interning as an associate at G3 Partners, a Seoul-based marketing agency for tech startups, running tech community engagements at coworking space and business community, ASPACE Philippines, and interning at workspace marketplace FlySpaces. He graduated with a BS Management Engineering at Ateneo de Manila University in 2019.